 pas de
diffťrence entre fichiers locaux ou distants.
pas de
diffťrence entre fichiers locaux ou distants.Idťe de base = pouvoir partager entre plusieurs clients et serveurs hťtťrogŤnes un mÍme systŤme de fichiers.
Une machine peut Ítre ŗ la fois client et serveur.
Un serveur NFS exporte ses directories pour qu'elles soient accessibles par des clients.
Si une directory est exportťe, c'est tout le sous-arbre qui est exportť.
Liste des directories exportťes dans /etc/exports.
Une station cliente sans disque (diskless) peut faire "comme si" elle avait un disque en montant des systŤmes distants.
Une station avec un disque local aura une hierarchie en partie locale et distante.
Pour les programmes du client pas de
diffťrence entre fichiers locaux ou distants.
Si deux clients ont montť la mÍme directory, ils en partagent les fichiers.
simplicitť de NFS.
clients et serveurs utilisant diffťrents
OS et diffťrentes machines.
Il est impťratif de dťfinir une bonne interface client/serveur.
Avantage d'une interface clairement dťfinie : possibilitť d'ťcrire de nouveaux clients et serveurs compatibles.
2 protocoles sont dťfinis.
1 protocole pour le mounting et 1 protocole pour la directory et l' accŤs aux fichiers.
C envoie ŗ S un chemin d'accŤs (le nom de la directory ŗ monter) et demande la permission de monter la directory chez lui.
L'endroit oý C va monter la directory n'est pas important pour S.
Si le chemin d'accŤs est correct et si la directory se trouve dans /etc/exports, S renvoie un file handle ŗ C.
Le handle est composť :
Un client peut monter des directory sans intervention humaine.
Ces clients ont un fichier /etc/rc shell script qui contient les commandes de mount et lancť automatiquement au boot.
C'est le static mounting.
Les versions rťcentes de Sun Unix ont l' automounting :
Des directory distantes sont associťes ŗ des directories locales, mais elles ne sont pas montťes, et leurs serveurs ne sont pas contactťs au boot.
La premiŤre fois qu'un client accŤde ŗ un fichier distant, les serveurs sont contactťs. Le premier qui rťpond gagne.
difficile de mettre en route le client ;
tolťrance aux fautes.
surtout utilisť
pour des systŤmes de fichiers read-only.
Les clients envoient des messages pour manipuler des directories, lire et ťcrire des fichiers et leurs attributs (taille, date de modification, propriťtaire, etc.).
Tous les appels systŤmes sont pris en charge par NFS sauf OPEN et CLOSE.
OPEN et CLOSE ne sont pas utiles :
aucune info sur les
fichiers ouvert est perdue (puisqu'il n'y en a pas).Un serveur NFS est stateless.
Fichier fermť verrous relachťs.
NFS est stateless, on ne peut pas associer de verrous ŗ l'ouverture d'un fichier.
Il faut un mťcanisme externe ŗ NFS pour gťrer le verouillage.
NFS utilise quand mÍme le systŤme de protection Unix (bits rwx pour le owner, group et world).
MAIS : le serveur NFS croit toujours le client pour valider un accŤs.
Que faire si le client ment ?
Utilisation de la cryptographie pour valider les requÍtes.
ProblŤme : les donnťes, elles, ne sont pas cryptťes.
Les clťs sont gťrťes par le NIS ( Network Information Service, ou yellow pages)
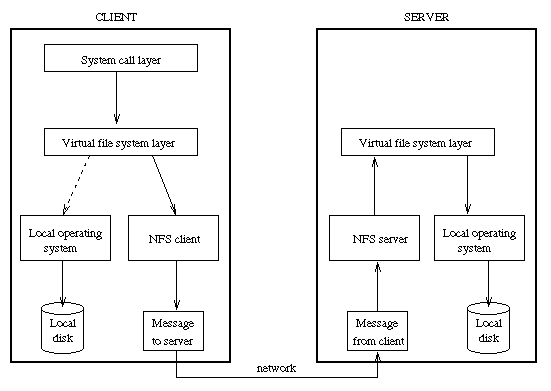
La couche VFS maintient une table pour chaque fichier ouvert.
Chaque entrťe est un v-node (virtual i-node). On indique si le fichier est local ou distant.
Exemple : la sťquence < MOUNT, OPEN, READ >.
Automatiquement, dŤs que le client a reÁu les 8ko demandťs, une nouvelle requÍte de 8ko est envoyťe.
C'est le read ahead.
Tant que les donnťes ťcrites sont < 8ko, elles sont accumulťes localement.
DŤs que le client a ťcrit 8ko, les 8ko sont envoyť au serveur.
Quand un fichier est fermť, ce qui reste ŗ ťcrire est envoyť au serveur.
Utilisation du caching :
les clients ont 2 caches : attributs et donnťes.
problŤmes de cohťrences.
 Retour au sommaire.
Retour au sommaire.
