![]()
|
|
Support de cours Réseaux EISTI |
|
Introduction
Nous allons étudier comment la couche "INTERCONNECTION" délivre
des datagrammes (ou informations) à travers des réseaux
interconnectés.
Nous aborderons la fragmentation de paquets et ces conséquences.
Principe d'un algorithme de routage
Un des protocoles les plus connus est RIP (RIP: ROUTING INFORMATION PROTOCOL)
également connu sous le nom d'un programme qui le met en œuvre
: routed . Le logiciel routed a été réalisé à
l'université de Californie : Berkeley. Il assure un routage cohérent
et permet l'échange d'informations d'accessibilité entre machines
sur les réseaux locaux de cette université. Il Utilise la diffusion
sur le réseau physique pour propager rapidement les informations de
routage. Il n'a pas été initialement conçu pour être
utilisé sur les réseaux grande distance. Routed s'appuie sur
des travaux de recherche antérieurs menés par le centre de
recherche de la compagnie Xerox (PARC: Palo Alto Research Center), à
Palo Alto. Il met en œuvre un protocole dérivé du protocole
d'informations de routage de Xerox (NS) et l'a généralisé
à un ensemble de familles de réseau.
La popularité de RIP, en dépit de légères
améliorations par rapport à ses précurseurs, ne tient
pas à ses mérites techniques. Au contraire, elle résulte
de la distribution de ce protocole avec les logiciels du célèbre
système d'exploitation UNIX 4 BSD Ainsi, de nombreux sites TCP/IP
ont adopté et commencé à utiliser routed et RIP, sans
en avoir étudié les caractéristiques techniques ni les
limitations. Une fois installé et opérationnel, il a
constitué la base du routage local et les groupes de recherches l'ont
adopté pour des réseaux plus grands.
Le fait le plus surprenant concernant RIP est peut-être d'avoir
été mis en œuvre bien avant que la norme (RFC plus exactement)
correspondante ne soit spécifiée. La plupart des mises en
œuvre sont dérivées du code de Berkeley et
l'interfonctionnement de ce protocole est limité par la
compréhension des détails et des subtilités non
commentés qu'en avaient les programmeurs. Avec l'apparition de nouvelles
versions, de nouveaux problèmes se sont posés un RFC est enfin
apparue en juin 1988.
Le protocole RIP sous-jacent est une application directe du routage à
vecteurs de distance utilisé pour les réseaux locaux. Il classe
les participants en machines passives ou actives. Une passerelle active propage
les routes qu'elle connaît vers les autres machines; les machines passives
écoutent les passerelles et mettent à jour leurs routes en
fonction des informations reçues, mais n'en diffusent pas
elles-mêmes. Habituellement, les passerelles utilisent RIP en mode
actif et les machines l'utilisent en mode passif.
Une passerelle utilisant RIP en mode actif diffuse un message toutes les
30 secondes. Le message contient des informations extraites de ses tables
de routage courantes de la passerelle. Chaque message est constitue d'une
partie contenant l'adresse IP d'un réseau et un entier mesurant la
distance de la passerelle vers ce réseau. RIP utilise une métrique
à nombre de sauts (hop count metric) pour mesurer la distance qui
la sépare d'une destination. Dans la métrique RIP, une passerelle
est située à une distance d'un saut d'un réseau directement
accessible, a deux sauts des réseaux accessibles par l'intermédiaire
d'une autre passerelle et ainsi de suite. Le nombre de sauts (number of HOP
OU hop count metric) mesure donc le nombre de passerelles que doit traverser
un datagramme pour atteindre sa destination, sur un chemin reliant une source
donnée à une destination donnée. Il doit être
clair que l'utilisation du nombre de sauts pour déterminer les plus
courts chemins ne conduit pas toujours à une solution optimale. Par
exemple, un chemin qui traverse trois réseaux Ethernet et comporte
trois sauts peut être nettement plus rapide qu'un chemin qui ne comporte
que deux sauts, mais emprunte deux liaisons séries basse vitesse.
Pour compenser les différences inhérentes à la technologie,
de nombreuses mises en œuvre de RIP utilisent des nombres de sauts
artificiellement élevés lorsqu'elles diffusent des informations
relatives des réseaux à bas débit.
Partenaires RIP actifs et passifs écoutent tous les messages et mettent
à jour leurs tables de routage, conformément à l'algorithme
de routage à vecteurs distance décrit précédemment.
Ainsi, dans l'interconnexion présentée
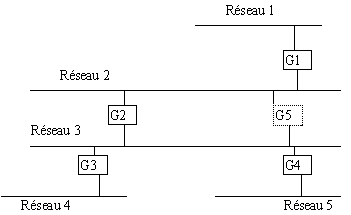
La passerelle Gl diffusera sur le réseau un message qui contient la
paire (1, 1), ce qui signifie que G1 peut atteindre le réseau 1 pour
un coût de 1. Les passerelles G2 et G5 reçoivent ces informations
et mettent leurs tables à jour en créant une route qui paisse
par la passerelle G1 pour atteindre le réseau 1 (pour un coût
de 2). Ultérieurement, les passerelles G2 et G5 propagent la paire
( 1, 2) lorsqu'elles diffusent leur message RIP sur le réseau 3. Le
cas échéant, toutes les passerelles et les machines créeront
une route vers le réseau 1.
RIP définit quelques règles d'amélioration des performances
et de la fiabilité. Ainsi, lorsqu'une passerelle apprend d'une autre
passerelle l'existence d'une nouvelle route, elle conserve cette dernière
jusqu'à ce qu'elle en connaisse une meilleure. Dans notre exemple,
si les passerelles G2 et G5 propagent des informations de routage indiquant
que le réseau 1 a un coût de 1, les passerelles G3 et G4
créeront une route passant par la première passerelle dont
elles auront reçu le message. Nous pouvons le résumer ainsi:
Pour empêcher l'oscillation entre deux ou plusieurs passerelles de même coût
RIP indique que les routes crées doivent être conservées jusqu'à ce qu'une route de coût strictement inférieur apparaisse.
Que se passe-t-il lorsque la passerelle qui a propagé les informations
de routage tombe en panne ? RIP indique que tous les récepteurs doivent
associer une temporisation aux routes acquises. Lorsqu'une passerelle
définit une route dans ses tables, elle lui associe une temporisation
et l'active. La temporisation doit être réarmée à
chaque fois que la passerelle reçoit un message RIP
référençant cette route. La route est invalidée
s'il s'écoule 180 secondes sans qu'elle soit de nouveau
référencée.
RIP doit prendre en compte trois types d'erreurs causés par l'algorithme
sous jacent. D'abord, l'algorithme ne détecte pas les boucles de
façon explicite, RIP doit donc supposer que ses partenaires sont fiables
ou prendre des précautions pour détecter les boucles. RIP doit
ensuite utiliser une petite valeur comme distance maximale possible (RIP
utilise la valeur 16) pour éviter les instabilités. Les
administrateurs de réseaux doivent utiliser un autre protocole pour
les interconnexions dans lesquelles le nombre de sauts avoisine normalement
la valeur 16 (de toute évidence, la petitesse de la valeur limite
du nombre de sauts de RIP le rend inutilisable dans les grands
réseaux).
Troisièmement, l'algorithme de routage à vecteurs de distance
utilisé par RIP entraîne une convergence lente (slow convergence)
ou un problème de valeur infinie (count to infinity) qui produit des
incohérences parce que les messages se propagent lentement à
travers le réseau. Le, choix d'une faible valeur infinie (16) limite
le phénomène de valeur infinie, sans pour autant
l'éviter.
L'incohérence des tables de routage n'est pas spécifique de
RIP. C'est un problème fondamental inhérent à tout protocole
à vecteurs de distance où les messages ne véhiculent
que des paires (réseau destination, distance). Considérons,
pour comprendre le problème, l'ensemble de passerelles de la figure
suivante :
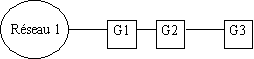
La figure représente les routes vers le réseau 1 pour l'interconnexion le la figure précédente.
La passerelle Gl accède directement au réseau 1. Sa table de routage comporte une route à laquelle est associée une distance 1. Cette route fait partie des informations de routage diffusées périodiquement. La passerelle G2 apprend la route de Gl, l'inscrit dans sa table de routage et propage les informations relatives à cette route, en indiquant une distance 2. Enfin, G3 apprend la route de G2 et propage les informations relatives à cette route en indiquant une distance 3.
Supposez maintenant que l'accès de G1 au réseau 1 tombe en panne. G 1 met immédiatement à jour sa table de routage et affecte une distance infinie (16) à 1a route correspondante. Dans la diffusion d'informations suivante, G1 diffuse le coût élevé associé à cette route. A Moins toutefois que le protocole ne comporte des mécanismes supplémentaires pour éviter l'apparition de ce phénomène, une autre passerelle peut, avant G1 propager des informations relatives à cette route. Supposez., en particulier, que G2 diffuse ses informations de routage juste après que l'accès de G1 au réseau 1 est tombé en panne. Dans ce cas, G 1 reçoit des messages de G2 et applique l'algorithme de routage à vecteurs de distance: elle constate que G2 l'informe de l'existence d'une route vers le réseau 1 dont le coût est inférieur au sien et en déduit que le coût d'accès au réseau 1 est de 3 sauts ( 2 sauts pour atteindre le réseau I depuis G2 plus un pour l'atteindre depuis Gl). Gl inscrit donc dans sa table de routage la route qui passe par G 2 pour atteindre le réseau 1.
Les diffusions RIP ultérieures de ces deux passerelles ne résolvent pas rapidement le problème. Au cycle de diffusion d'informations de route suivante, G1 diffuse le contenu de l'entrée de sa table. Lorsque G2 apprend que la route vers le réseau 1 a un coût de 3, elle recalcule le coût associé à cette route, celui-ci prend la valeur 4. au troisième tour, G1 reçoit de G2 des informations qui signalent une augmentation du coût associé à la route vers le réseau 1. Elle augmente donc la valeur dans sa table de routage. Celle-ci vaut maintenant 5. et elles poursuivent ce processus jusqu'à atteindre la valeur infinie de RIP.
Protocoles
utilisés pour les grands
réseaux
RIP est simple à mettre en place mais ne résout pas tous les problèmes.
Deplus vue le nombre de réseaux, les tables de routage RIP peuvent devenir énormes. En plus des informations statiques, généralement on utilise une route par défaut.
Lorsque l'on envoie un datagramme à une passerelle, cette dernière regarde sa table de routage pour voir si elle connaît la prochaine passerelle pour atteindre le réseau. Si oui elle lui remet de datagramme sinon, elle remet ce dernier à une passerelle spécifique qui procédera de même. Généralement, les passerelles RIP connaissent toutes les routes du réseau de l'entreprise et ignorent les routes vers les réseaux extérieures.
Elles transmettent donc tous les datagrammes destinés à l'extérieur à une autre passerelle. Cette passerelle est souvent appelée passerelle extérieurs par opposition à "passerelles intérieures". Les passerelles extérieures vont utiliser d'autres algorithmes tels que SPF(Link-state, Shortest First).
Ce protocole suppose que toutes les passerelles l'utilisant connaissent la topologie de l'ensemble des réseaux qu'elles gèrent.
EGP (Exterior Gateway Protocol) est un protocole qui est souvent mis en œuvre sur des passerelles qui font l'interconnexion de sites avec des réseaux fédérateurs. Le principe d'EGP est simple. Chaque passerelle ne connaît que ces voisins immédiats et met en place une route par défaut sur l'un de ces voisins pour pouvoir router les paquets vers des réseaux qu'elle ne connaît pas.
Toutes ces méthodes permettent donc à IP de trouver un chemin lorsqu'il existe. Cependant il existe aujourd'hui encore des cas qui posent problèmes.
Le but d'IP est de trouver un chemin pour envoyer un datagramme. Ce datagramme va circuler de passerelles en passerelles. Ces passerelles sont connectées sur un support physique qui peut avoir des MTU (Maximum Transfert Unit) différent (c'est-à-dire qui échange des trames de longueurs différentes).
![]()
Le réseau1 dispose d'un MTU M1, il est connecté au réseau
2, via G1, qui dispose d'un MTU M2, qui ... via Gn-1, qui dispose d'un MTU
Mn.
Supposons qu'une machine du réseau 1 envoie un datagramme IP de longueur
L à destination d'une machine sur le réseau N, alors 5 cas
de figures peuvent se présenter:
Conclusion
IP envoie des datagrammes de machines à machines.
IP garantie qu'il fera tout son possible pour envoyer le datagramme (Best
effort).
IP peut détruire un datagramme.
IP ne garantie pas qu'un datagramme émis arrive à l'identique
sur l'autre machine. Il peut fragmenter le datagramme et émettre ces
fragments sur différents chemins en fonction des tables de routages.
IP n'est pas un protocole fixe, mais est en perpétuel
évolution.
IP ne fixe pas seul les routes, il utilise d'autres protocoles (GGP,RIP,
…)
|
|
Support de cours Réseaux EISTI |
|
